How we test that Aleph is not fooling itself
An agent can fail because of the model. That's normal. What we didn't want was not knowing whether the model failed or the harness that runs tools, permissions and edits failed.
When a coding agent gets something wrong, the comfortable explanation is "the model couldn't do it." Sometimes that's true. But when you're building the agent, that answer is not enough. The model may have emitted the right tool call and the harness may have parsed it incorrectly. Or the tool may have run in the wrong directory. Or the loop may have swallowed an error. Or the native route may have lost half a call because it arrived through streaming in two pieces.
So we added a new evaluation suite for Aleph. Not to measure whether a model is smart. To measure whether the harness does what it claims to do.
Two different problems
There are two questions that sound similar, but are not:
- Does the model solve the task? That tests the whole system: model, prompt, tools, context, parsing, permissions, editing, terminal.
- Does the harness work? That needs controlled responses, because if the model improvises you don't know who to blame.
Benchmarks like SWE-bench are great for the first question. For the second, they're too noisy. If they fail, it could be a thousand different things. To catch harness bugs we needed something less glamorous and much more useful: a fake model.
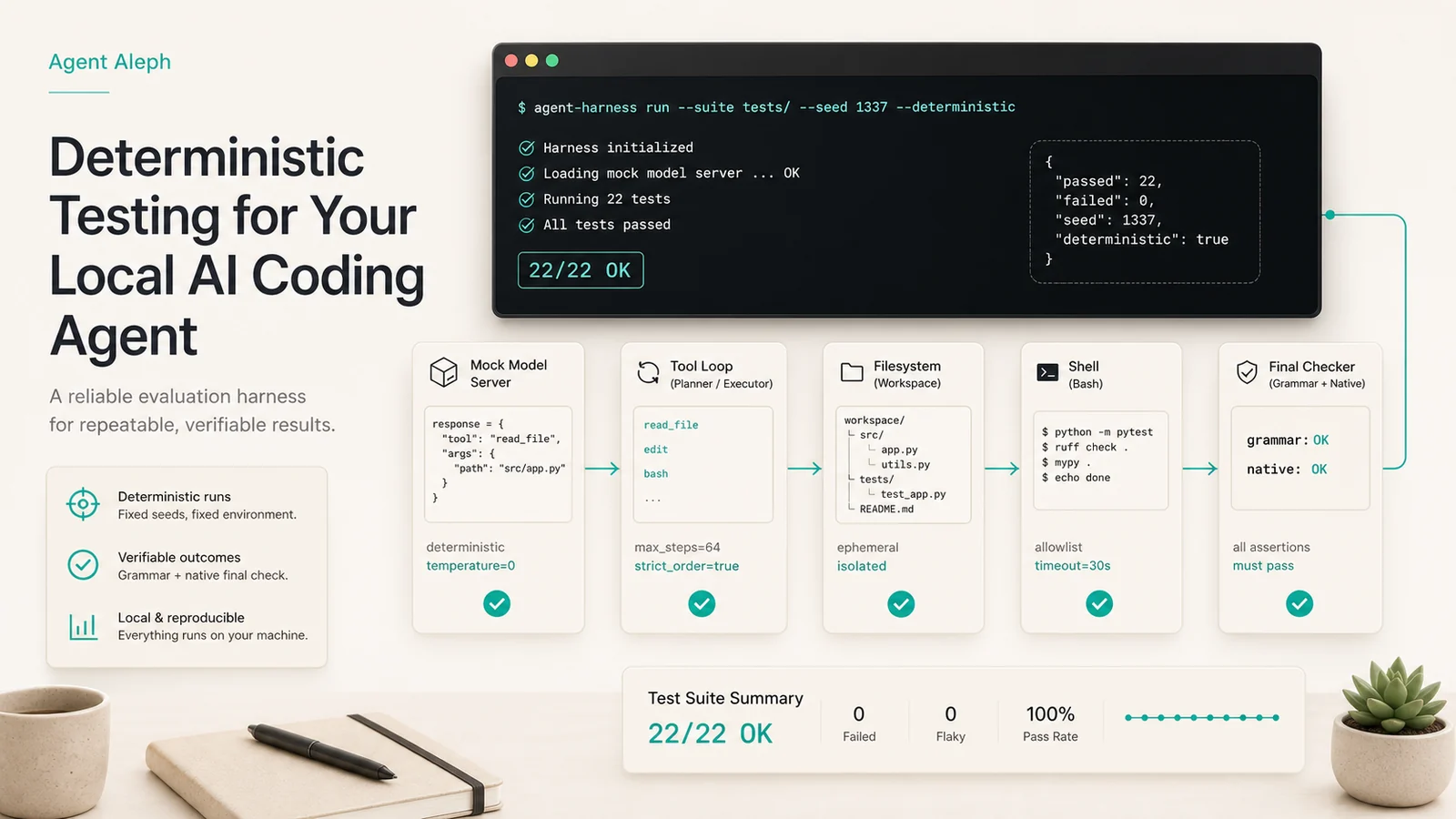
The fake model
The new --mock-harness mode starts a local server compatible with the llama-server API. From the outside it looks like an OpenAI-compatible model: it responds to /health, /v1/models and /v1/chat/completions. But internally it does not "think". It reads the test case and returns exactly the tool call we want.
cargo run --bin agent_eval -- \
--mock-harness \
--routes grammar,native \
--out /tmp/opencode/aleph-harness-mock \
--context-size 8192 --max-tokens 1024The important bit: the suite does not skip the agent. It still goes through run_turn, which uses the same run_inner as the app. So it tests the real loop: messages, streaming, tool calls, argument validation, permissions, execution, tool results and finalization.
What it covers
The mock suite tests both the grammar and native routes. The first forces JSON with GBNF. The second uses native tool calls, including the awkward case: a call whose arguments arrive fragmented through streaming.
The cases include reads, writes, edits, bash, tool errors, invalid arguments, unknown tools, Plan-mode denial, loop detection, large-result capping to protect context, invalid JSON recovery in the grammar route, and multiple native tool calls in a single step.
The most valuable test is not the one that confirms everything goes well. It's the one that forces the system to fail in a known way and checks that it recovers.
We still test with a real model
The mock does not replace the real model. It complements it. For integration we added --port, which lets the eval reuse the llama-server already loaded by the app. That way we don't start a second server, don't fight for VRAM, and test the exact model Aleph is using.
./target/debug/agent_eval \
--port 38115 \
--model-name ornith-1.0-9b-Q4_K_M.gguf \
--routes auto \
--suite smoke10 \
--out /tmp/opencode/ornith9b-smoke10 \
--context-size 25344 --max-tokens 1024With Ornith 9B, the smoke10 suite passed 10/10. That suite does test the whole system: the model has to choose tools, read, edit, run tests and respond. If it fails there, we're in model+agent integration territory. If the mock fails, that's on us.
Why this matters
A local agent has a lot of small moving parts. Each one seems obvious until it isn't: an absolute path that should not escape the project, a tool that returns too much text, a command that fails but still has to go back to the model, native output arriving in fragments, a loop that repeats the same read as if reality might change on the fourth try.
The deterministic suite makes those pieces boring. And in infrastructure, boring is a compliment.
Now we can change the prompt, touch the parser, adjust permissions or modify tools with a fast safety net. After that, yes, it makes sense to run larger benchmarks or different models. First make sure the floor doesn't move. Then we can see how high the agent climbs.