Cómo probamos que Aleph no se miente solo
Un agente puede fallar por el modelo. Eso es normal. Lo que no queríamos era no saber si falló el modelo o si falló el harness que ejecuta herramientas, permisos y ediciones.
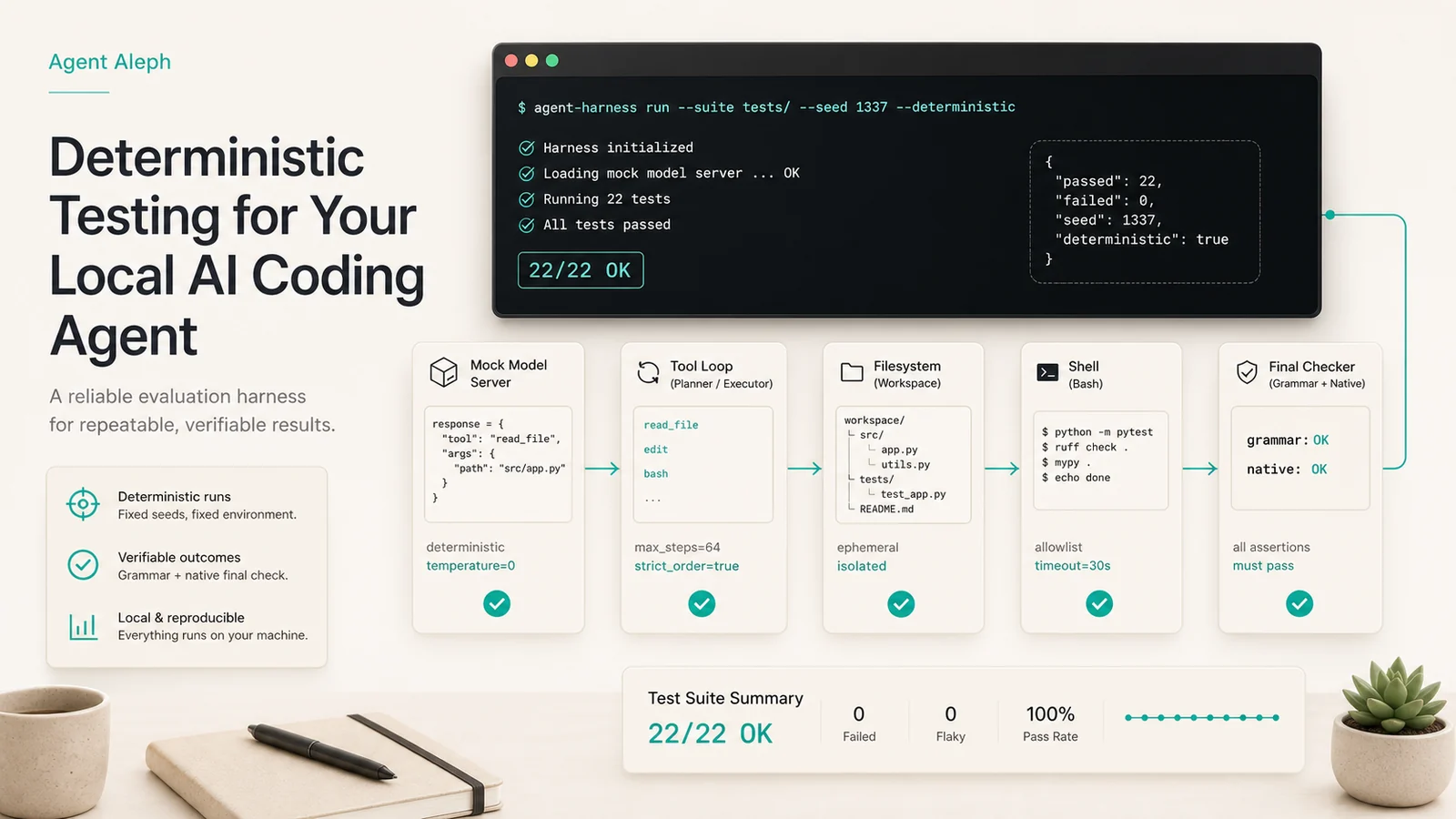
Cuando un agente de código se equivoca, la explicación cómoda es "el modelo no pudo". A veces es cierto. Pero si estás construyendo el agente, esa respuesta no alcanza. El modelo puede haber emitido bien el tool call y el harness puede haberlo parseado mal. O la herramienta pudo ejecutar en el directorio incorrecto. O el loop pudo tragarse un error. O la ruta nativa pudo perder media llamada porque llegó por streaming en dos pedazos.
Entonces agregamos una suite de evaluación nueva para Aleph. No para medir si un modelo es inteligente. Para medir si el harness hace lo que dice que hace.
Dos problemas distintos
Hay dos preguntas que parecen iguales, pero no lo son:
- ¿El modelo resuelve la tarea? Eso prueba el sistema completo: modelo, prompt, herramientas, contexto, parsing, permisos, edición, terminal.
- ¿El harness funciona? Eso hay que probarlo con respuestas controladas, porque si el modelo improvisa no sabés a quién culpar.
Benchmarks como SWE-bench son buenísimos para la primera pregunta. Pero para la segunda son demasiado ruidosos. Si fallan, puede ser por mil cosas. Para cazar bugs del harness necesitábamos algo menos glamoroso y mucho más útil: un modelo falso.
El modelo falso
El nuevo modo --mock-harness levanta un servidor local compatible con la API de llama-server. Desde afuera parece un modelo OpenAI-compatible: responde a /health, /v1/models y /v1/chat/completions. Pero por dentro no "piensa". Lee el caso de prueba y devuelve exactamente el tool call que queremos.
cargo run --bin agent_eval -- \
--mock-harness \
--routes grammar,native \
--out /tmp/opencode/aleph-harness-mock \
--context-size 8192 --max-tokens 1024Lo importante: la suite no saltea el agente. Sigue entrando por run_turn, que usa el mismo run_inner de la app. O sea, prueba el loop real: mensajes, streaming, tool calls, validación de argumentos, permisos, ejecución, resultados de herramientas y finalización.
Qué cubre
La suite mock prueba tanto la ruta grammar como la ruta native. La primera fuerza JSON con GBNF. La segunda usa tool calls nativos, incluyendo el caso incómodo: una llamada que llega fragmentada por streaming.
Los casos incluyen lectura, escritura, edición, bash, errores de herramienta, argumentos inválidos, tools inexistentes, denegación en modo Plan, detección de loops, truncado de resultados grandes para cuidar el contexto, recuperación de JSON inválido en la ruta grammar y múltiples tool calls nativas en un solo paso.
El test más valioso no es el que confirma que todo sale bien. Es el que obliga al sistema a fallar de una forma conocida y comprueba que se recupera.
También probamos con un modelo real
El mock no reemplaza al modelo real. Lo complementa. Para integración agregamos --port, que permite reutilizar el llama-server que ya tiene cargado la app. Así no levantamos otro servidor, no peleamos por VRAM y probamos exactamente el modelo que está usando Aleph.
./target/debug/agent_eval \
--port 38115 \
--model-name ornith-1.0-9b-Q4_K_M.gguf \
--routes auto \
--suite smoke10 \
--out /tmp/opencode/ornith9b-smoke10 \
--context-size 25344 --max-tokens 1024Con Ornith 9B la suite smoke10 pasó 10/10. Esa suite sí mide el sistema completo: el modelo tiene que elegir herramientas, leer, editar, ejecutar tests y responder. Si falla ahí, ya estamos en terreno de integración modelo+agente. Si falla el mock, es culpa nuestra.
Por qué esto importa
Un agente local tiene muchas piezas pequeñas. Cada una parece obvia hasta que deja de serlo: una ruta absoluta que no debería salir del proyecto, una herramienta que devuelve demasiado texto, un comando que falla pero igual debe volver al modelo, un output nativo que llega en fragmentos, un loop que repite la misma lectura como si eso fuera a cambiar la realidad.
La suite determinística hace que esas piezas sean aburridas. Y en infraestructura, aburrido es un cumplido.
Ahora podemos cambiar el prompt, tocar el parser, ajustar permisos o modificar herramientas con una red de seguridad rápida. Después sí, cuando el harness está firme, tiene sentido correr benchmarks más grandes o modelos distintos. Primero que el piso no se mueva. Después vemos qué tan alto llega el agente.